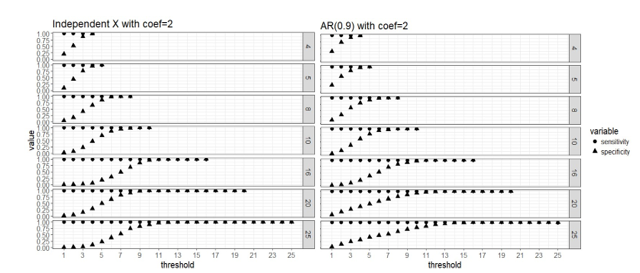
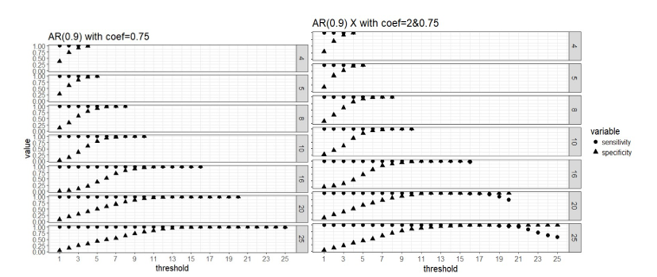
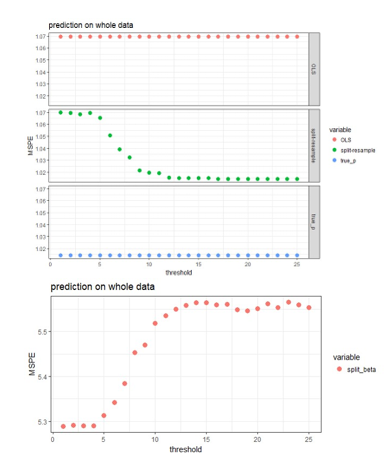
I was given an opportunity to attend a leadership conference one year. I was pretty early in my career, maybe five or so years in, and had just started managing a team. One question they asked attendees really stuck with me: “Do your people know what you expect of them?” We all answered, “Yes, they have goals and objectives for the year.” That’s not what the facilitators meant. “No, does your team know, day in and day out, what you expect them to bring to work every day?” This got me thinking about success not just as ticking off the boxes on your to-do list or in your end of year objectives, but more about the way we show up every day to do our jobs. I put a list together of all the most successful people I knew – this list consisted of senior leaders, but also my peers. I listed out traits about each of them that embodied who they were, both professionally and personally (if I knew them in that regard). Given I’m an analyst in heart and mind, I started clustering these traits together. Every time I was asked in an interview by an interviewee “What makes someone successful in this role?” I come back to this list. Truth be told, this list isn’t just for analyst or data scientist; I believe anyone who shows up each and every day and works in this way will be a success.
1. Be passionately curious
What a cliché, right? But, Albert Einstein even said it: “I have no special talent. I am only passionately curious.” The thing is, the people who LOVE what they do, I mean genuinely get excited about everything that comes across their desk, will be seen as a true team player. Sure, not all projects you are given will invoke pure passion, but if you decide to make the most of all projects, if you recognize there is something to learn from every opportunity you are given, then you will show up passionately each and every time. And that curiosity? When you are passionate about your work you are more interested in digging in deeper, in uncovering those “ah-ha” nuggets. Those who show pure passion and a sense of curiosity are the best types of people to work with.
2. Be honest
I know I’m tough. I expect a lot; I’ve been told I push people harder than they are used to being pushed. I always tell my team I need to know their breaking point, not because I want them to break. We want to always be pushing ourselves to just before our breaking points, and then pull back, push again…and I bet you start to notice your breaking point moves. You get stronger and can handle more as your skillset grows. I expect honesty so that I know when you are close to your breaking point. I once had a direct report break down on me – they were overloaded and couldn’t take on more work, admitting they had felt this way for a few weeks. I had been asking them for more because they kept saying “YES”. We sat together and prioritized their work and calendar; we got the workload to a manageable amount. This person grew from this experience. And when they left my team for another said, “I don’t know that anyone will push me the way you did. I’m better because of it.”
3.Be respectful
We know our world and the challenges we are faced with. We rarely know all the issues our peers and colleagues are facing in their day to day jobs (nevertheless their personal life). Someone else’s job may seem easy to you, or unnecessary even. I once said I didn’t understand the role of the client service group, the sales team. It’s not that I didn’t see the sales they brought in, it just did not seem “that hard” to me. BOY was I wrong. I spent some time in a more consultative role once and, while I could hang, I hated it. I tell you this story because it taught me the importance of valuing all roles on a project and team. There are parts I do not wish to play; I am thankful every day there are people who love sales because without them, what projects would I have had to analyze?
4. Challenge the data and others (but do it respectfully)
We live in a data rich world – data is streaming in from all angles. Not all data is perfect. When something seems off, when your gut is telling you the data is wrong, chances are your gut is right. Pressure test the data and insights, making sure they measure up to benchmarks or your overall knowledge of the data. Challenge yourself, too. Ask yourself if you’ve done all you can do to deliver a top-quality product. Challenge your colleagues and peers – it is our job to ensure quality work is delivered to the end user/client, which means we need to help one another pressure test the work. I also encourage my team to challenge me – if there is a better way to do something than I am proposing, challenge me to think differently. Loop back to point #3, though, and be sure you are respecting the opinions and ideas of others.
5. Take accountability
I think about this in two ways (a) when you are assigned to work, take ownership and see it through, and (b) when you make a mistake, fess up to it right away. I’ve worked with people above me who quit putting effort into work they weren’t interested in and it sent a message to the team: if you don’t like a project, it’s ok to phone it in. I’m here to say that is not true. That project is important to someone else – they are expecting your best effort. When a mistake happens, I encourage people to let me know. It’s rarely as big of a deal as they feel it is in the moment, but I promise I will always have their back and will take the fall so long as I know they are behind the scenes cleaning things up.
What often amazes analysts and data scientists when I share this list is that there isn’t a single technical skill listed. Those skills can be taught – these softer skills are harder to teach, are often innate in us. They require time from our own selves to develop and nurture. I encourage you to analyze the way you work – are you lacking in any of these areas? Can you come up with ways to strengthen these skills? Feel free to reach out if you are interested in discussing further – I’m always happy to help.
About the Author

Sandy Steiger is the Director of The Center for Analytics & Data Science (CADS) at Miami University. Sandy earned her Masters degree at Miami in statistics after graduating with a Bachelor’s from Mount St. Joseph University in mathematics and business. She worked in industry for fifteen years, most recently as the Vice President of Insights at 84.51 before joining CADS in April 2019.